Анализ временных рядов (АВР) – простейший метод восстановления зависимости в детерминированном случае, исходя из заданного временного ряда. Основная задача – экстраполяция (прогноз) – самый постой способ прогноза рыночной ситуации. Суть его – распространение тенденций, сложившихся в прошлом и будущем.
Многие рыночные процессы обладают инертностью, что учитывают при прогнозах. На определенный период следует максимально принимать во внимание вероятность изменения условий функционирования рынка. Делается предположение, что система эволюционирует в достаточно стабильных условиях. Чем система крупнее, тем вероятнее сохранение параметров без изменения, но не на большой срок. Рекомендуется, чтобы период прогноза не превышал 1/3 длительности исходной временной базы.
Временной ряд – серия числовых величин, полученных через регулярные промежутки времени Основное положение, на котором базируется использование временных рядов на предприятии – факторы, влияющие на отклик изучаемой системы, действующие в прошлом, настоящем и подобным образом будут действовать в недалеком будущем.
Цель анализа – оценка и выделение факторов с целью прогноза дальнейшего поведения системы и выработки рациональных УР. Прогноз на основе АВР – краткосрочный, в отношении периода, которого принимается, характеристики изучаемого явления существенно не изменяются. Большинство прогнозных ошибок связано с тем, что прогноз предполагает сохранение прошлых тенденций в будущем. Эта гипотеза редко оправдывается в экономической и общественной жизни.
ВР могут стать плохой основой для разработки прогноза, поэтому методы прогнозирования и АВР применяют для краткосрочного прогнозирования достаточно стабильных и хорошо изученных процессов. Прогнозируемый период не превышает 25-30% исходной временной базы. При использовании уравнения регрессии прогнозные расчеты проводят для оптимистических и пессимистических оценок исходных параметров. Отсюда получают 2 вида прогнозов: оптимистический и пессимистический. Прогнозную оценку, получаемую на основе методов прогнозирования, используют как индикатор желаемой величины прогнозного параметра.
ВР включает в себя:
1) тренд – показывает общий тип изменений, долгосрочного уменьшения и увеличения ряда,
2) сезонные колебания – колебания вокруг тренда, которые возникают на регулярной основе.
Обычно регулярные колебания возникают в период до года. Могут отслеживаться при ежеквартальных, ежемесячных, еженедельных и т.д. наблюдениях.
3) циклические колебания – возникают в периоды свыше года. Часто присутствуют в финансовых данных и связаны с резким спадом, бурным ростом и периодом застоя.
4) случайные колебания – непредсказуемые колебания в большинстве реальных ВР.
Требования к данным временного ряда
Все методы прогнозирования используют математическую статистику, поэтому необходимо, чтобы все данные были сопоставимы, достаточно представлены для проявления закономерности однородные и устойчивые. Невыполнение одного из этих требований делает бессмысленным применение математической статистики.
1. Сопоставимость достигается в результате одинакового подхода, к наблюдениям на разных этапах формирования временного ряда. Данные во временных рядах должны выражаться в одних и тех же единицах измерениях, иметь одинаковый шаг наблюдений, рассчитываться для одного и того же интервала времени по одной и той же методике, охватывать одни и те же элементы, принадлежащие одной территории и относящиеся к неизменной совокупности.
Несопоставимость данных чаще всего проявляется в стоимостных показателях. Даже в тех случаях когда значения этих показателей фиксируются в неизменных ценах. Такого рода несопоставимость временных рядов невозможно устранить чисто формальными методами.
2. Представительность данных характеризуется, прежде всего, полнотой представленных данных. Достаточное число наблюдений определяется в зависимости от цели проводимого исследования. Если целью является описательный статистический анализ, то в качестве изучаемого интервала времени можно выбрать любой интервал по своему усмотрению. Если же цель исследования - построение модели прогнозирования, то число данных исходного временного ряда должно не менее чем в 3 раза превышать период прогноза и не должно быть менее 7 данных. В случае использования квартальных или месячных данных для исследования сезонности и прогнозирования сезонных процессов, исходный временной ряд должен содержать квартальные либо месячные данные не менее чем за 4 года, даже если прогноз требуется на 1 или 2 месяца.
3.Однородность – отсутствие нетипичных аномальных наблюдений, а так же изломов тенденций (изменение). Аномальность приводит к смещению оценок и как следствие к искажению результатов анализа. Формально аномальность проявляется как сильный скачок или спад с последующим приблизительным восстановлением предыдущего уровня. Для диагностики аномальных наблюдений разработаны различные стандартные критерии.
4. Устойчивость – это свойство отражает преобладание закономерности над случайностью в изменениях уровня и ряда. На графиках устойчивых временных рядов даже визуально прослеживается закономерность. А на графиках неустойчивых временных рядов – изменения представлены хаотично. Поэтому поиск закономерностей в таких временных рядах не имеет смысла.
Модели временных рядов
Статистические методы исследования исходят из предположения возможности представления значений временного ряда в виде комбинации нескольких компонентов, отражающих закономерность и случайность развития. В частности для краткосрочных прогнозов применяется аддитивная (адаптивная) и мультипликативная модели.
1. Адаптивная (аддитивная)
Y(t) = T(t) +S(t) + F(t)
t - номер временного интервала
T(t) – тренд развития (долговременная тенденция)
S(t) – сезонная компонента
Е(t) – остаточная компонента
2. Мультипликативная
Y(t) = T(t)*S(t)*F(t)
При односильном постоянстве амплитуды сезонной волны целесообразно использовать аддитивную модель. При изменении амплитуды сезонной волны соответствие с тенденцией среднего уровня используется мультипликативная модель. Иногда используются модели смешанного типа, они дают более точный результат, но содержательно плохо интерпретируются. Применение мультипликативной модели обусловлено тем что в некоторых временных рядах значение сезонной компоненты представляет собой определенную долю трендового значения. Практика показывает что случаи, когда сезонные колебания исследуемого процесса велики и не очень стабильны, мультипликативная модель дает плохие результаты. Сезонная компонента характеризует устойчивые и внутригодичные колебания уровней – она проявляется в некоторых показателях представленных квартальными или месячными данными.
В моделях с аддитивной и мультипликативной компонентой общая процедура анализа примерно одинаковая.
Надо сделать:
1) расчет значений сезонной компоненты
2) вычитание сезонной компоненты из фактических значений – этот процесс называется десезонализации (устранение сезонности)
3) расчет ошибок как разности между фактическими и трендовыми значениями
4) расчет среднего отклонения или средней квадратической ошибки
В прогнозировании также применяются модели кривых роста.
Кривые роста – математические функции предназначенные для аналитического выравнивания временного ряда.
Для описания кривых роста используются следующие функции
2. Парабола Y(t) = a+bt =ct 2
3. Гипербола Y(t) = a +b/t
4. Степенная
5. Показательная
6. Логарифмическая
7. Кривая Джонсона
8. Модифицированная экспонента
Сглаживание временных рядов
Выявление основной тенденции развития называется выравниванием или сглаживание временного ряда. Методы выявления основной тенденции – это методы выравнивания.
Один из наиболее простых приемов обнаружения общей тенденции развития явления – это укрупнение интервала динамического ряда. Для выявления тенденций развития используется метод скользящего среднего или метод экспоненциального сглаживания. Оба метода субъективны в отношении выбора параметров сглаживания. И именно в корректном выборе параметров проявляется интуиция исследователя.
Метод скользящего среднего – крайне субъективен и на результаты сглаживания сильно влияет длина периода сглаживаний. При небольших периодах не удается выявить трендовую компоненту. При больших периодах происходят значительные потери данных на концах анализируемого интервала.
Скользящая средняя порядка L – это временной ряд состоящий из среднеарифметических и среднеарифметических L в соседних значениях функции Y по всем возможным значениям времени. В качестве L – нечетное число, 3, 5,7 - трехточечные, пятиточечные и семиточечные.
Трехточечная схема : среднее значение будет рассчитываться по 3м значениям Yi, одно из которых относится к прошлому периоду, второе к искомому и 3 к будущему периоду. При i = 1 не существует прошлого значение, то в первой точке невозможно рассчитать сглаженное значение. При i = 2 то среднее значение будет средним арифметическим.
В последней точке исходного интервала скользящее среднее также невозможно рассчитать из-за отсутствия будущего значения по отношению к рассчитываемому.
Метод экспоненциального сглаживания – в отличие от скользящего среднего может быть использован для краткосрочным прогнозов в будущей тенденции на один период вперед. Именно поэтому метод обладает явным преимуществом перед предыдущим.
Алгоритм расчета сглаженных значений в любой точке ряда основан на 3х величинах: наблюдаемом значении Yi в данной точке, рассчитанном сглаженном значении для предшествующей точки ряда и некоторым заранее заданным коэффициентам сглаживания, постоянным по всему ряду.
Fi = α*Yi +(α-1)*Fi
Yi –фактическое значение итой точки ряда.
Сглаженное значение для предшествующей точки ряда - (альфа-1)
Альфа может принимать любые значения от 0 до1, но обычно на практике ограничиваются интервалом от 0,2 до 0.5
Метод Хольта. L t =k*Y t +(1-k)*(L t-1 -T t-1), где
L t – сглаженная величина на текущий период;
K – коэффициент сглаживания ряда;
Y t – текущие значение ряда (например, объём продаж);
L t-1 – сглаженная величина за предыдущий период;
T t-1 – значение тренда за предыдущий период.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Основные методы прогнозирования
Методы социального прогнозирования
Методы финансового прогнозирования
Методы экономического прогнозирования
Статистические методы прогнозирования
Экспертные методы прогнозирования
Анализ временных рядов
Структурные компоненты временного ряда
Основные методы прогнозирования
Прогнозирование - это предсказание будущего на основании накопленного опыта и текущих предположений относительно него.
Прогнозирование представляет собой сложный процесс, по ходу которого необходимо решать большое количество различных вопросов. Для его производства следует применять в сочетании различные методы прогнозирования , которых на сегодняшний день существует огромное множество, но на практике используются всего 15 - 20. На наиболее популярных из них мы и остановимся.
Метод экспертных оценок. Суть данного метода заключается в том, что в основе прогноза лежит мнение одного специалиста или группы специалистов, которое основано на профессиональном, практическом и научном опыте. Различают коллективные и индивидуальные экспертные оценки, часто используется при оценке персонала.
Метод экстраполяции. Основная идея экстраполяции - изучение сложившихся как в прошлом, так и настоящем стойких тенденций развития предприятия и перенос их на будущее. Различают прогнозную и формальную экстраполяцию. Формальная - основывается на предположении о том, что в будущем сохранятся прошлые и настоящие тенденции развития предприятия; при прогнозной - настоящее развитие увязывают с гипотезами о динамике предприятия с учетом того, что в будущем изменится влияние на него различных факторов. Следует знать, что методы экстраполяции лучше применять на начальной стадии прогнозирования, чтобы выявить тенденции изменения показателей.
Методы моделирования. Моделирование - это конструирование модели на основании предварительного изучения объекта и процессов, выделение его существенных признаков и характеристик. Прогнозирование с использованием моделей включает в себя ее разработку, экспериментальный анализ, сопоставление результатов предварительных прогнозных расчетов с фактическими данными состояния процесса или объекта, уточнение и корректировку модели.
Метод экономического прогнозирования (экономический анализ) заключается в том, что какой либо экономический процесс или явление, имеющие место на предприятии, расчленяются на части, после чего выявляется влияние и взаимосвязь этих частей на ход и развитие процесса, а также друг на друга. При помощи анализа можно раскрыть сущность такого процесса, а также определить закономерности его изменения в будущем, всесторонне оценить пути достижения поставленных целей. Поскольку экономический анализ - это необъемлемая часть и один из элементов логики прогнозирования, он должен осуществляться на макро-, мезо- и микроуровнях. Используется при планировании производства на предприятии. прогнозирование экономический временной экспертный
Процесс экономического анализа можно подразделить на несколько стадий:
* постановка проблемы, определение критериев оценки и целей;
* подготовка необходимой для анализа информации;
* аналитическая обработка информации после ее изучения;
* оформление результатов.
Балансовый метод. Данный метод основан на разработке балансов, которые представляют собой систему показателей, где первая часть, характеризующая ресурсы по источникам их поступления, равна второй, отражающей распределение их по всем направлениям расхода.
При помощи балансового метода воплощается в жизнь принцип пропорциональности и сбалансированности, который применяется при разработке прогнозов. Его суть заключается в увязке потребностей предприятия в различных видах сырьевых, материальных, финансовых и трудовых ресурсах с возможностями производства продукта и источниками ресурсов. Таким образом, система балансов, которую используют в прогнозировании, включает: финансовые, материальные и трудовые балансы. В каждую из данных групп входит еще ряд балансов.
Нормативный метод - один из основных методов прогнозирования. В настоящее время ему стало придаваться большое значение. Его сущность заключается в технико-экономических обоснованиях прогнозов с использованием нормативов и норм. Последние применяются при расчете потребности в ресурсах, а также показателей их использования.
Программно-целевой метод (ПЦМ). В сравнении с другими методами данный метод является сравнительно новым и недостаточно разработанным. Он начал широко применяться только в последние годы. ПЦМ тесно связан с уже рассмотренными методами и предполагает разработку прогноза начиная с оценки итоговых потребностей на основании целей развития предприятия при дальнейшем определении и поиске эффективных средств и путей их достижения, а также ресурсного обеспечения.
Суть ПМЦ заключается определении основных целей развития предприятия, разработки взаимосвязанных мероприятий по их достижению в заранее определенные сроки при сбалансированном обеспечении ресурсами, а также с учетом эффективного их использования.
Кроме прогнозирования, ПМЦ применяется при создании комплексных целевых программ, которые представляют собой документ, где отражены цель и комплекс производственных, организационно-хозяйственных, социальных и других мероприятий и заданий, увязанных по исполнителям, срокам осуществления и ресурсам.
Методы социального прогнозирования
Социальное прогнозирование как исследование с широким охватом объектов анализа опирается на множество методов. При классификации методов прогнозирования выделяются основные их признаки, позволяющие их структурировать по: степени формализации; принципу действия; способу получения информации.
Степень формализации в методах прогнозирования в зависимости от объекта исследования может быть различной; способы получения прогнозной информации многозначны, к ним следует отнести: методы ассоциативного моделирования, морфологический анализ, вероятностное моделирование, анкетирование, метод интервью, методы коллективной генерации идей, методы историко-логического анализа, написания сценариев и т.д. Наиболее распространенными методами социального прогнозирования являются методы экстраполяции, моделирования и экспертизы.
Экстраполяция означает распространение выводов, касающихся одной части какого-либо явления, на другую часть, на явление в целом, на будущее. Экстраполяция основывается на гипотезе о том, что ранее выявленные закономерности будут действовать в прогнозном периоде. Например, вывод об уровне развития какой-либо социальной группы можно сделать по наблюдениям за ее отдельными представителями, а о перспективах культуры - по тенденциям прошлого.
Экстраполяционный метод отличается многообразием - насчитывает не менее пяти различных вариантов. Статистическая экстраполяция - проекция роста населения по данным прошлого - это один из важнейших методов современного социального прогнозирования.
Моделирование - это метод исследования объектов познания на их аналогах - вещественных или мысленных.
Аналогом объекта может быть, например, его макет, чертеж, схема и т.д. В социальной сфере чаще используются мысленные модели. Работа с моделями позволяет перенести экспериментирование с реального социального объекта на его мысленно сконструированный дубликат и избежать риска неудачного, тем более опасного для людей управленческого решения. Главная особенность мысленной модели и состоит в том, что она может быть подвержена каким угодно испытаниям, которые практически состоят в том, что меняются параметры ее самой и среды, в которой она (как аналог реального объекта) существует. В этом огромное достоинство модели. Она может выступить и как образец, своего рода идеальный тип, приближение к которому может быть желательно для создателей проекта.
Самый практикуемый метод прогнозирования - экспертная оценка. По мнению Е.И.Холостовой, «экспертиза есть исследование трудноформализуемой задачи, которое осуществляется путем формирования мнения (подготовки заключения) специалиста, способного восполнить недостаток или несистемность информации по исследуемому вопросу своими знаниями, интуицией, опытом решения сходных задач и опорой на «здравый смысл».
Существуют такие сферы социальной жизни, в которых невозможно использовать другие методы прогнозирования , кроме экспертных. Прежде всего, это касается тех сфер, где отсутствует необходимая и достаточная информация о прошлом.
При экспертной оценке состояния либо отдельной социальной сферы, либо ее составляющего элемента, либо ее компонентов учитывается ряд обязательных положений, методических требований.
Прежде всего - оценка исходной ситуации:
Факторы, предопределяющие неудовлетворительное состояние;
Направления, тенденции, наиболее характерные для данного состояния ситуации;
Особенности, специфика развития наиболее важных составных;
Наиболее характерные формы работы, средства, с помощью которых осуществляется деятельность.
Второй блок вопросов включает в себя анализ деятельности тех организаций и служб, которые осуществляют эту деятельность. Оценка их деятельности идет по выявлению тенденций в их развитии, их рейтинга в общественном мнении.
Экспертную оценку проводят специальные центры экспертизы, научные информационно-аналитические центры, лаборатории экспертов, экспертные группы и отдельные эксперты.
Методика экспертной работы включает в себя ряд этапов:
Определяется круг экспертов;
Выявляются проблемы;
Намечается план и время действий;
Разрабатываются критерии для экспертных оценок;
Обозначаются формы и способы, в которых будут выражены результаты экспертизы (аналитическая записка, «круглый стол», конференция, публикации, выступления экспертов).
Итак, социальное прогнозирование опирается на различные методы исследования, основными из которых являются экстраполяция, моделирование и экспертиза.
Методы финансового прогнозирования
Финансовое прогнозирование по методу бюджетирования
Процесс бюджетирования является составной частью финансового планирования - процесса определения будущих действий по формированию и использованию финансовых ресурсов.
Бюджетирование - процесс построения и исполнения бюджета предприятия на основе бюджетов отдельных подразделений.
Бюджет - детализированный план деятельности предприятия на ближайший период, который охватывает доход от продаж, производственные и финансовые расходы, движение денежных средств, формирование прибыли предприятия.
Бюджеты подразделяются на два основных вида:
Операционный бюджет, отражающий текущую (производственную) деятельность предприятия;
Финансовый бюджет, представляющий собой прогноз финансовой отчетности.
План прибылей и убытков - основной документ операционного бюджета. Содержит данные о величине и структуре выручки от продаж, себестоимости реализованной продукции и конечных финансовых результатах.
Финансовый бюджет составляется с учетом информации, содержащейся в бюджете о прибылях и убытках.
Одним из основных этапов бюджетирования является прогнозирование движения денежных средств.
Бюджет движения денежных средств - это план денежных поступлений и платежей. При расчете бюджета движения денежных средств принципиально важно определить время поступлений и платежей, а не время исполнения хозяйственных операций.
Значение общего бюджета для предприятия раскрывается через следующие его функции:
Планирование операций, обеспечивающих достижение целей предприятия;
Координация различных видов деятельности и отдельных подразделений. Согласование интересов отдельных работников и групп в целом по предприятию;
Стимулирование руководителей всех рангов на достижение целей своих центров ответственности;
Контроль текущей деятельности, обеспечение плановой дисциплины;
Основа для оценки выполнения плана центрами ответственности и их руководителей;
Средство обучения менеджеров.
В отличие от формализованных отчетах о прибылях и убытках или бухгалтерского баланса, бюджет не имеет стандартизированной формы, которая должна строго соблюдаться. Бюджет может иметь бесконечное количество видов и форм. Форма и структура бюджета зависят от многих факторов: масштаба деятельности предприятия; достаточности и доступности исходной информации; состояния нормативной базы предприятия; от квалификации и опыта разработчика.
Финансовое прогнозирование по методу « процента от продаж
Существует два основнх метода финансового прогнозирования. Один из них - метод бюджетирования - представлен в разделе 3 методических указаний. Напомним, что он основан на концепции денежных потоков и его аналогом служит расчет финансовой части бизнес-плана.
Второй метод называется метод «процента от продаж» (первая модификация) или метод «формулы» (вторая модификация). Его преимущества - простота и лаконичность. Применяется для ориентировочных расчетов потребности во внешнем финансировании.
Факторы, оказывающие влияние на величину потребности в дополнительном финансировании:
Планируемый темп роста объема реализации;
Исходный уровень использования основных средств;
Капиталоемкость (ресурсоемкость) продукции;
Рентабельность продукции;
Дивидендная политика.
Метод «процента от продаж» - метод пропорциональной зависимости показателей деятельности предприятия от объема реализации.
Все вычисления по методу «процента от продаж» (методу «формулы») делаются на основе следующих предположений:
1. Переменные затраты, текущие активы и текущие обязательства при наращивании объема продаж на определенное количество процентов увеличиваются, в среднем, на столько же процентов. Это означает, что и текущие активы, и текущие пассивы будут составлять в плановом периоде прежний процент от выручки;
2. Процент увеличения стоимости основных средств рассчитывается под заданный процент наращивания оборота в соответствие с:
а) технологическими условиями бизнеса;
б) учетом наличия недогруженных основных средств на начало периода прогнозирования;
в) в соответствие со степенью материального и морального износа наличных основных средств и т.п.;
3. Долгосрочные обязательства и акционерный капитал берутся в прогноз неизменными;
4. Нераспределенная прибыль прогнозируется с учетом нормы распределения чистой прибыли на дивиденды и чистой рентабельности реализованной продукции.
Для прогнозирования нераспределенной прибыли к нераспределенной прибыли базового периода прибавляют прогнозируемую чистую прибыль и вычитают дивиденды.
Методы экономического прогнозирования
Особое место в классификации методов экономического прогнозирования занимают так называемые комбинированные методы, которые объединяют различные другие методы. Например, коллективные экспертные оценки и методы моделирования или статистические и опрос экспертов.
В качестве информации используется фактографическая и экспертная информация.
При классификации методов прогнозирования необходимо иметь в виду, что содержательная систематизация методов прогнозирования должна определяться самим объектом прогнозирования, экономическими процессами развития и их закономерностями.
С точки зрения оценки возможных результатов и путей прогнозного научно-технического развития прогнозы можно классифицировать по трем этапам: исследовательскому, программному и организационному.
Задачей исследовательского прогноза является определение возможных результатов будущего развития и выбор из множества возможных вариантов одного или нескольких положительных результатов. Так, например, развитие средств вычислительной техники можно отразить в росте их быстродействия, увеличении объема памяти и диапазона логических возможностей.
Основная цель этого этапа состоит в раскрытии широкой гаммы принципиально возможных перспектив в виде одной или ряда научно-технических проблем, подлежащих решению в течение прогнозируемого периода.
Программный аспект прогноза заключается в определении возможных путей достижения желаемых и необходимых результатов; ожидаемого по времени реализации каждого из возможных варианта и степени достоверности в успешном достижении некоторого результата по тому или иному варианту.
Организационная сторона прогноза включает в себя комплекс организационно-технических мероприятий, обеспечивающих достижение определенного результата по тому или иному варианту. В организационном аспекте исходят из представления о наличных экономических ресурсах и накопленном научном потенциале. Здесь должна быть сформулирована обоснованная гипотеза развития комплекса организационных параметров науки, дана вероятностная оценка рекомендуемой схеме распределения ресурсов и перспективам роста научного потенциала на прогнозируемый период.
Рассмотренные этапы научно-технического развития, как правило, выступают комплексно и находятся во взаимосвязи.
Статистические методы прогнозирования
Статистические методы прогнозирования охватывают разработку, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных (в том числе непараметрических методов наименьших квадратов с оцениванием точности прогноза, адаптивных методов, методов авторегрессии и других); развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования, в том числе методов анализа субъективных экспертных оценок на основе статистики нечисловых данных; разработку, изучение и применение методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научная база статистических методов прогнозирования -- прикладная статистика и теория принятия решений. Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, то есть функции, определенной в конечном числе точек на оси времени. При этом временной ряд часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные) помимо времени, напр., объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи -- интерполяция и экстраполяция.
Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794--1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Метод наименьших модулей, сплайны и другие методы экстраполяции применяются реже, хотя их статистические свойства зачастую лучше. Накоплен опыт прогнозирования индекса инфляции и стоимости потребительской корзины. Оказалось полезным преобразование (логарифмирование) переменной -- текущего индекса инфляции. Оценивание точности прогноза (в частности, с помощью доверительных интервалов) -- необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, напр., строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Так, предложены непараметрические методы доверительного оценивания точки наложения (встречи) двух временных рядов для оценки динамики технического уровня собственной продукции и продукции конкурентов, представленной на мировом рынке. Применяются также эвристические приемы, не основанные на вероятностно статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения, -- основной на настоящий момент статистический аппарат прогнозирования. Подчеркнем, что нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно. Однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от ноля в непараметрической постановке, строить доверительные границы для прогноза. Весьма важна проблема проверки адекватности модели, а также проблема отбора факторов. Априорный список факторов, оказывающих влияние на отклик, обычно весьма обширен. Его желательно сократить, и отдельное направление современных исследований посвящено методам отбора «информативного множества признаков». Однако эта проблема пока еще окончательно нерешена. Проявляются необычные эффекты. Так, установлено, что обычно используемые оценки степени полинома имеют в асимптотике геометрическое распределение. Перспективны непараметрические методы оценивания плотности вероятности и их применение для восстановления регрессионной зависимости произвольного вида. Наиболее общие результаты в этой области получены с помощью подходов статистики нечисловых данных. К современным статистическим методам прогнозирования относятся также модели авторегрессии, модель Бокса Дженкинса, системы эконометрических уравнений, основанные как на параметрических, так и на непараметрических подходах. Для установления возможности применения асимптотических результатов при конечных (т.н. «малых») объемах выборок полезны компьютерные статистические технологии. Они позволяют также строить различные имитационные модели. Отметим полезность методов размножения данных (бутстрепметодов). Системы прогнозирования с интенсивным использованием компьютеров объединяют различные методы прогнозирования в рамках единого автоматизированного рабочего места прогнозиста.
Прогнозирование на основе данных, имеющих нечисловую природу, например, прогнозирование качественных признаков основано на результатах статистики нечисловых данных. Весьма перспективными для прогнозирования представляются регрессионный анализ на основе интервальных данных, включающий, в частности, определение и расчет рационального объема выборки, а также регрессионный анализ нечетких данных. Общая постановка регрессионного анализа в рамках статистики нечисловых данных и ее частные случаи -- дисперсионный анализ и дискриминантный анализ (распознавание образов с учителем), -- давая единый подход к формально различным методам, полезны при программной реализации современных статистических методах прогнозирования. Основные процедуры обработки прогностических экспертных оценок -- проверка согласованности, кластер анализ и нахождение группового мнения.
Проверка согласованности мнений экспертов, выраженных ранжировками, проводится с помощью коэффициентов ранговой корреляции Кендалла и Спирмена, коэффициента ранговой конкордации Кендалла и Смита. Используются параметрические модели парных сравнений -- Терстоуна, БредлиТерриЛьюса -- и непараметрические модели теории люсианов. Полезна процедура согласования ранжировок и классификаций путем построения согласующих бинарных отношений. При отсутствии согласованности разбиение мнений экспертов на группы сходных между собой проводят методом ближайшего соседа или другими методами кластерного анализа (автоматического построения классификаций, распознавания образов без учителя). Классификация люсианов осуществляется на основе вероятностно-статистической модели. Используют также различные методы построения итогового мнения комиссии экспертов. Своей простотой выделяются методы средних арифметических и медиан рангов. Компьютерное моделирование позволило установить ряд свойств медианы Кемени, часто рекомендуемой для использования в качестве итогового (обобщенного, среднего) мнения комиссии экспертов в случае, когда их оценки даны в виде ранжировки.
Интерпретация закона больших чисел для нечисловых данных в терминах теории экспертного опроса такова: итоговое мнение устойчиво, т.е. мало меняется при изменении состава экспертной комиссии, и при росте числа экспертов приближается к «истине». При этом предполагается, что ответы экспертов можно рассматривать как результаты измерений с ошибками, все они -- независимые одинаково распределенные случайные элементы, вероятность принятия определенного значения убывает по мере удаления от некоторого центра -- «истины», а общее количество экспертов достаточно велико. В конкретных задачах прогнозирования необходимо провести классификацию рисков, поставить задачу оценивания конкретного риска, провести структуризацию риска, в частности, построить деревья причин (в другой терминологии, деревья отказов) и деревья последствий (деревья событий).
Центральной задачей является построение групповых и обобщенных показателей, например, показателей конкурентоспособности и качества. Риски необходимо учитывать при прогнозировании экономических последствий принимаемых решений, поведения потребителей и конкурентного окружения, внешнеэкономических условий и макроэкономического развития России, экологического состояния окружающей среды, безопасности технологий, экологической опасности промышленных и иных объектов. Современные компьютерные технологии прогнозирования основаны на интерактивных Статистические методы прогнозирования и использовании баз эконометрических данных, имитационных (в том числе на основе применения метода статистических испытаний) и экономико-математических динамических моделей, сочетающих экспертные, математико-статистические и моделирующие блоки.
Экспертные методы прогнозирования
Эксперт - квалифицированный специалист, привлекаемый для формирования оценок относительно объекта прогнозирования. Экспертная группа - коллектив экспертов, сформированный по определенным правилам. Суждение эксперта или экспертной группы относительно поставленной задачи прогноза называется экспертной оценкой; в первом случае используется термин «индивидуальная экспертная (прогнозная) оценка», а во втором - «коллективная экспертная (прогнозная) оценка». Способность эксперта создавать на базе профессиональных знаний, интуиции и опыта достоверные оценки относительно объекта прогнозирования характеризует его компетентность. Последняя имеет количественную меру, называемую коэффициентом компетентности. То же справедливо и в отношении экспертной группы: компетентность экспертной группы - это ее способность создавать достоверные оценки относительно объекта прогнозирования, адекватные мнению генеральной совокупности экспертов; количественная мера компетентности экспертной группы определяется на основе обобщения коэффициентов компетентности отдельных экспертов, входящих в группу.
Экспертный метод прогнозирования - метод прогнозирования, базирующийся на экспертной информации. В теоретическом аспекте правомерность использования экспертного метода подтверждается тем, что методологически правильно полученные экспертные суждения удовлетворяют двум общепринятым в науке критериям достоверности любого нового знания: точности и воспроизводимости результата. В таблице даны наименования и краткие характеристики основных экспертных методов, используемых при разработке социально-экономических прогнозов.
Анализ временных рядов
Цели, методы и этапы анализа временных рядов
Практическое изучение временного ряда предполагает выявление свойств ряда и получение выводов о вероятностном механизме, порождающем этот ряд. Основные цели при изучении временного ряда следующие:
Описание характерных особенностей ряда в сжатой форме;
Построение модели временного ряда;
Предсказание будущих значений на основе прошлых наблюдений;
Управление процессом, порождающим временной ряд, путем выборки сигналов, предупреждающих о грядущих неблагоприятных событиях.
Достижение поставленных целей возможно далеко не всегда как из-за недостатка исходных данных (недостаточная длительность наблюдения), так из-за изменчивости со временем статистической структуры ряда.
Перечисленные цели диктуют в значительной мере, последовательность этапов анализа временных рядов:
графическое представление и описание поведения ряда;
выделение и исключение закономерных, неслучайных составляющих ряда, зависящих от времени;
исследование случайной составляющей временного ряда, оставшейся после удаления закономерной составляющей;
построение (подбор) математической модели для описания случайной составляющей и проверка ее адекватности;
прогнозирование будущих значений ряда.
При анализе временных рядов используются различные методы, наиболее распространенными из которых являются:
корреляционный анализ, используемый для выявления характерных особенностей ряда (периодичностей, тенденций и т. д.);
спектральный анализ, позволяющий находить периодические составляющие временного ряда;
методы сглаживания и фильтрации, предназначенные для преобразования временных рядов с целью удаления высокочастотных и сезонных колебаний;
методы прогнозирования.
Структурные компоненты временного ряда
Как уже отмечалось, в модели временного ряда принято выделять две основные составляющие: детерминированную и случайную (рис.1). Под детерминированной составляющей временного ряда понимают числовую последовательность, элементы которой вычисляются по определенному правилу как функция времени t. Исключив детерминированную составляющую из данных, мы получим колеблющийся вокруг нуля ряд, который может в одном предельном случае представлять чисто случайные скачки, а в другом - плавное колебательное движение. В большинстве случаев будет нечто среднее: некоторая иррегулярность и определенный систематический эффект, обусловленный зависимостью последовательных членов ряда.
В свою очередь, детерминированная составляющая может содержать следующие структурные компоненты:
Тренд g, представляющий собой плавное изменение процесса во времени и обусловленный действием долговременных факторов. В качестве примера таких факторов в экономике можно назвать: а) изменение демографических характеристик популяции (численности, возрастной структуры); б) технологическое и экономическое развитие; в) рост потребления.
Сезонный эффект s, связанный с наличием факторов, действующих циклически с заранее известной периодичностью. Ряд в этом случае имеет иерархическую шкалу времени (например, внутри года есть сезоны, связанные с временами года, кварталы, месяцы) и в одноименных точках ряда имеют место сходные эффекты.
Размещено на Allbest.ru
...Подобные документы
Сущность экономического прогнозирования, характеристика основных форм предвидения. Предвидение внутренних и внешних условий деятельности. Виды прогнозов и технология прогнозирования. Методы прогнозирования: экспертные, статистические, комбинированные.
курсовая работа , добавлен 22.12.2009
Изучение методов прогнозирования развития: экстраполяции, балансового, нормативного и программно-целевого метода. Исследование организации работы эксперта, формирования анкет и таблиц экспертных оценок. Анализ математико-статистические моделей прогноза.
контрольная работа , добавлен 19.06.2011
Понятие, функции и методы прогнозирования – научно-обоснованного суждения о возможных состояниях объекта в будущем, об альтернативных путях и сроках их достижения. Классификация методов прогнозирования: социосинергетика, "коллективная генерация идей".
курсовая работа , добавлен 10.03.2011
Сущность основных понятий в области прогнозирования. Признаки классификации, виды прогнозов и их характеристика. Экстраполятивный и альтернативный подходы. Статистический и экспертный методы, их разновидности. Содержание и этапы разработки плана сбыта.
реферат , добавлен 25.01.2010
Сущность и структура системы социально-экономического прогнозирования, виды прогнозов и возможности их применения для предприятия. Мероприятия по планированию деятельности предприятия, их уровни и назначение. Экспертные методы, пути прогнозирования.
реферат , добавлен 27.06.2010
Суть форсайта как метода долгосрочного прогнозирования. Методы прогнозирования, применяемые в форсайтах. Критические технологии, экспертные панели. Особенности корпоративного форсайта. Применение метода корпоративных технологических "дорожных карт".
курсовая работа , добавлен 26.11.2014
Знакомство с основными проблемами прогнозирования, способы решения. Сглаживающие модели прогнозирования. Анализ подходов искусственного интеллекта: биологическая аналогия, архитектура сети, гибридные методы. Работа программы по прогнозу нейронных сетей.
дипломная работа , добавлен 27.06.2012
Методы прогнозирования, используемые в инновационном менеджменте. Шкалы и методы измерений в экспертном оценивании. Организация и проведение экспертизы. Получение обобщенной оценки на основе индивидуальных оценок экспертов, согласованность мнений.
курсовая работа , добавлен 07.05.2013
курсовая работа , добавлен 24.12.2011
Понятия прогнозирования и планирования. Почему прогнозировать сложно. Различные виды неопределенностей. Критерии классификации планирования. Основные техники и виды планирования. Основные методы прогнозирования. Планирование как управленческое решение.
Таблица Excel с исходными данными имеет следующий вид (рис. 2.33).
Рис. 2.33. Таблица Excel с исходными данными
При анализе временных рядов широко применяются графические методы. Это объясняется тем, что табличное представление временного ряда и описательные характеристики чаще всего не позволяют понять характер процесса, а по графику временного ряда можно сделать определенные выводы, которые потом могут быть проверены с помощью расчетов. Графический анализ ряда обычно задает направление его дальнейшего анализа.
Выделим диапазон ячеек А2:К2 и, используя команду График вкладки Вставка (рис. 2.34), построим график (рис. 2.35).

Рис. 2.34. Вкладка Вставка . Команда График

Рис. 2.35. График – Динамика продаж автомашин
До вставки линии тренда получите еще четыре копии графика, чтобы каждый тип линии тренда был построен на отдельном графике. Для вставки линии тренда, щелкните правой кнопкой мыши на одном из значений данных графика и выберите команду Добавить линию тренда , как показано на рис. 2.36.

Рис. 2.36. Команда Добавить линию тренда
контекстного меню
В диалоговом окне Формат линии тренда (рис. 2.37) выбираются предлагаемые типы линии тренда и активизируются опции показывать уравнение на диаграмме и поместить на диаграмму величину достоверности аппроксимации.

Рис. 2.37. Выбраны параметры линии тренда
В результате получим графики следующего вида (рис. 2.38 -2.).

Рис. 2.38. Тип линии тренда - Линейная

Рис. 2.39. Тип линии тренда - Логарифмическая

Рис. 2.40. Тип линии тренда – Полиномиальная

Рис. 2.41. Тип линии тренда - Степенная

Рис. 2.42. Тип линии тренда – Экспоненциальная
В качестве аппроксимирующей функции выбран полином второй степени – парабола, так как имеет наибольшее значение R 2 =0,9905, по этому типу тренда и построен прогноз на два шага вперед (рис. 2.43). В нашем примере прогнозируется число проданных автомашин на 11 и 12 неделях (рис. 2.44).

Рис. 2.43. Задан прогноз на два периода вперед

Рис. 2.44. Прогноз на два периода вперед
Так же для построения прогноза можно использовать встроенную статистическую функцию ТЕНДЕНЦИЯ. Заполним диапазон ячеек L1:M1 соответственно числами 11 и 12. Так как функция ТЕНДЕНЦИЯ дает массив ответов, то перед ее вызовом необходимо выделить диапазон ответов, в нашем случае L2:M2. Используя кнопку Мастера функций , вызовем диалоговое окно функции и заполним поля аргументов, как показано на рис. 2.45.

Рис. 2.45. Статистическая функция ТЕНДЕНЦИЯ
По окончании ввода формулы: =ТЕНДЕНЦИЯ(B2:K2;B1:K1;L1:M1) нажмите комбинацию клавиш Ctrl+Shift+Enter .
Результат вычислений показан на следующем рис. 2.46.
Получили следующий прогноз, если предприятие сохранит динамику продаж автомобилей, то на 11 неделе оно продаст 78 автомашин, а на 12 неделе – 84.
Линейная регрессия
В таблице заданы два временных ряда: первый из них представляет нарастающую по кварталам прибыль коммерческого банка (У ), второй ряд – процентную ставку этого банка по кредитованию юридических лиц (Х ) за тот же период (табл. 3).
Требуется:
1. Построить однофакторную модель регрессии;
2. Оценить прибыль банка при заданной (принимается пользователем самостоятельно) процентной ставке;
3. Отобразить на графике исходные данные, результаты моделирования.
Таблица 3
Таблица с исходными данными в Excel имеет следующий вид (рис. 2.47).

Рис. 2.47. Таблица с исходными данными
Для вычисления параметров модели составим расчетную таблицу следующего вида (рис. 2.48).

Рис. 2.48. Расчетная таблица
Эта же таблица в режиме индикации формул выглядит так, как показано на следующем рис. 2.49.

Рис. 2.49. Расчетная таблица в режиме
индикации формул
В ячейки С19 и С20 введены формулы для вычисления параметров а 1 и а 0 (рис. 2.50):


Рис. 2.50. Формулы для вычисления параметров а 1 и а 0
Значения самих параметров приведены на рис. 2.51.

Рис. 2.51. Значения параметров а 1 и а 0
Построенная модель зависимости прибыли от величины процентной ставки имеет вид:
Для того чтобы определить прибыль при величине процентной ставке равной 30%, необходимо подставить значение х в полученную модель.
В ячейку С22 введена следующая формула (рис 2.52):

Рис. 2.52. Формула для вычисления прогнозной величины прибыли
Прогнозное значение прибыли составит 13 тыс. руб. (рис. 2.53).

Рис. 2.53. Прогнозное значение прибыли
Рассчитаем таблицу остатков (рис. 2.54).

Рис. 2.54. Таблица остатков
Таблица остатков в режиме индикации формул имеет следующий вид (рис. 2.55).

Рис. 2.55. Таблица остатков в режиме индикации формул
Величина отклонения от линии регрессии вычисляется по следующей формуле:
В ячейку С38 введена формула для вычисления величины отклонения с использованием встроенной математической функции КОРЕНЬ (рис. 2.56).

Рис. 2.56. Встроенная математическая функция КОРЕНЬ
Величина отклонения от линии регрессии составляет 3,4401 (рис. 2.57).

Рис. 2.57. Величина отклонения от линии регрессии
На следующем этапе рассчитываются верхняя граница прогноза и нижняя. Для расчета доверительного интервала воспользуемся следующей формулой:
 ,
,
которая введена в ячейку С40.
Коэффициент t a является табличным значением t – статистики Стьюдента при заданном уровне значимости a и числе наблюдений. Если задать вероятность попадания прогнозируемой величины внутрь доверительного интервала, равную 90% (a = 0,01), число степеней свободы df = 10-1-1, то t a =1,8595.
Значение U=6,804 (рис. 2.58).
Рис. 2.58. Величина доверительного интервала
Для расчета верхней и нижней границ прогноза соответственно вводим в ячейки С42 и С43 формулы, как показано на следующем рис. 2.59.

Рис. 2.59. Формулы для расчета границ прогноза
Верхняя граница прогноза равна 19,81 тыс. руб., нижняя – 6,20 тыс. руб. (рис. 2.60).

Рис. 2.60. Значения границ прогноза
График исходных данных и результаты моделирования приведены на рис. 2.61.
 Рис. 2.61. График модели парной регрессии
Рис. 2.61. График модели парной регрессии
Для вычисления параметров модели можно было также использовать встроенные статистические функции, такие как НАКЛОН, ОТРЕЗОК, ЛИНЕЙН, СТОШУХ и др.
Функция НАКЛОН вычисляет наклон линии регрессии, в нашем примере это параметр а 1 .
Функция ОТРЕЗОК вычисляет параметр а 0 .
Функция ЛИНЕЙН одновременно вычисляет оба эти параметра. Перед вводом функции необходимо выделить диапазон ответов (две ячейки), а после заполнения аргументов функции нажать комбинацию клавиш Ctrl+Shift+Enter .
Функция СТОШУХ вычисляет стандартную ошибку, в нашем примере это величина S y .
Диалоговое окно встроенной статистической функции НАКЛОН с введенными аргументами показано на рис. 2.62.

Рис. 2.62. Встроенная статистическая функция НАКЛОН
Диалоговое окно встроенной статистической функции ОТРЕЗОК с введенными аргументами показано на рис. 2.63.

Рис. 2.63. Встроенная статистическая функции ОТРЕЗОК
Диалоговое окно встроенной статистической функции ЛИНЕЙН с введенными аргументами показано на рис. 2.64.

Рис. 2.64. Встроенная статистическая функция ЛИНЕЙН
Диалоговое окно встроенной статистической функции СТОШУХ с введенными аргументами показано на рис. 2.65.

Рис. 2.65. Встроенная статистическая функция СТОШУХ
Результат вычислений по встроенным статистическим функциям показан на рис. 2.65.

Рис. 2.66. Результат вычислений по встроенным статистическим функциям
Так же для построения модели можно использовать встроенный инструмент Пакета анализа Регрессия . Для этого на вкладке Данные выберите команду Анализ данных (рис. 2.67).

Рис. 2.67. Вкладка Данные . Команда Анализ данных
В появившемся диалоговом окне Анализ данных выберите инструмент Регрессия (рис. 2.68).

Рис. 2.68. Диалоговое окно Анализ данных .
Инструмент Регрессия
Заполните аргументы диалогового окна Регрессия , как показано на рис 2.69.

Рис. 2.69. Параметры инструмента Регрессия
Excel сгенерирует лист отчета, содержащий следующие таблицы:
· регрессионная статистика (рис. 2.70);
· дисперсионный анализ (рис. 2.71 – 2.72);
· таблица остатков (рис. 2.73),
а также построит график остатков (рис. 2.74).

Рис. 2.70. Регрессионная статистика

Рис. 2.71. Дисперсионный анализ

Рис. 2.72. Дисперсионный анализ. Значения коэффициентов

Рис. 2.73. Вывод остатка
График остатков имеет следующий вид (рис. 2.74).

Рис. 2.74. График остатков
При выполнении этого задания, значения коэффициентов уравнения парной регрессии а 1 и а 0 определялись тремя способами: методом наименьших квадратов, при помощи встроенных статистических функций и используя инструмент Регрессия . В каждом случае был получен один и тот же результат, что говорит о правильности расчета этих параметров.
Методы прогнозирования временных рядов
1. Прогнозирование как задача анализа временного ряда. Детерминированная и случайная составляющие: способы их выделения и оценки.
Прогнозирование – это научное выявление вероятностных путей и результатов предстоящего развития явлений и процессов, оценка показателей процессов для более или менее отдаленного будущего.
Изменение состояния наблюдаемого явления (процесса) характеризуется совокупностью параметров x1, x2, … , xt,…, измеренных в последовательные моменты времени. Такая последовательность называется временным рядом.
Анализ временных рядов – одно из направлений науки прогнозирования.
Если одновременно рассматриваются несколько характеристик процесса, то в этом случае говорят о многомерных временных рядах.
Под детерминированной (закономерной) составляющей временного ряда x1, x2, … , xn понимается числовая последовательность d1, d2, … , dn, элементы которой вычисляются по определенному правилу как функция времени t.
Если исключить из ряда детерминированную составляющую, то оставшаяся часть будет выглядеть хаотично. Ее называют случайной компонентой ε1, ε2, … , εn.
Модели разложения временного ряда на детерминированную и случайную компоненты:
1. Аддитивная модель:
xt = dt + εt, t=1,…n
2. Мультипликативная модель:
xt = dt · εt, t=1,…n
Если мультипликативную модель прологарифмировать, то получим аддитивную модель для логарифмов xt.
В детерминированной компоненте выделяют:
1) Тренд (trt) – плавно изменяющаяся нециклическая компонента, описывающая чистое влияние долговременных факторов, эффект которых сказывается постепенно.
2) Сезонная компонента (St) – отражает повторяемость процессов во времени.
3) Циклическая компонента (Ct) – описывает длительные периоды относительного подъема и спада.
4) Интервенция – существенное кратковременное воздействие на временной ряд.
Модели тренда:
– линейная: trt = b0 + b1t
– нелинейные модели:
полиномиальная: trt = b0 + b1t + b2t2 + … + bntn
логарифмическая: trt = b0 + b1 ln(t)
логистическая:
экспоненциальная: trt = b0 · b1t
параболическая: trt = b0 + b1t + b2t2
гиперболическая: trt = b0 + b1 /t
Тренд используется для долгосрочного прогноза.
Выделение тренда:
1) Метод наименьших квадратов (время – фактор, временной ряд – зависимая переменная):
xti = f (ti, θ)+εt i=1,…n
f – функция тренда;
θ – неизвестные параметры модели временного ряда.
εt – независимые и одинаково распределенные случайные величины.
Если минимизировать функцию, можно найти параметры θ.
2) Применение разностных операторов
![]()
Выделение сезонных эффектов
Пусть m – число периодов, p – величина периода.
St = St+p, для любых t.
1) Оценка сезонной компоненты
а) Сезонные эффекты на фоне тренда
Для аддитивной модели xt = trt + St + εt оценка:
Если необходимо, чтобы сумма сезонных эффектов равнялась 0, то переходят к скорректированным оценкам сезонных эффектов:

Для мультипликативной модели xt = trt * St * εt:
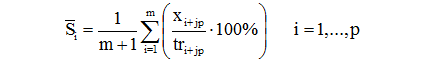
б) При наличии в ряде циклической компоненты (метод скользящих средних)
Идея метода: каждое значение исходного ВР заменяется средним значением на интервале времени, длина которого выбирается заранее. Выбранный интервал как бы скользит вдоль ряда.
Скользящее среднее при медианном сглаживании: t=med (xt-m,xt-m+1, …,xt+m)
При средне арифметическом сглаживании:
xt=1/(2m+1)(xt-m+xt-m+1+…+xt+m), если р – четный,
xt=1/(2m)(1/2*xt-m+xt-m+1+…+1/2*xt+m) если р – нечетный.
Для аддитивной модели xt = trt +Ct + St + εt.
Для упрощения обозначений: начнем нумерацию величин с единицы, изменим нумерацию исходного ряда так, чтобы величине x соответствовал член xt.
– скользящее среднее с периодом p, построенное по xt.
Для мультипликативной модели – перейти к логарифмам и получить мультипликативную модель.
xt = trt · Ct · St · εt
yt = log xt, dt = log trt, gt = log Ct, rt = log St, δt = log εt
yt = dt + gt + rt + δt
2) Удаление сезонной компоненты (сезонное выравнивание)
а) При наличии оценок сезонной компоненты:
Для аддитивной модели – путем вычитания из начальных значений ряда полученных сезонных оценок .
Для мультипликативной модели – путем деления начальных значений ряда на соответствующие сезонные оценки и умножением на 100%.
б) Применение разностных операторов
где В – оператор сдвига назад.
Разностный оператор второго порядка:
Если ВР одновременно содержит тренд и сезонную компоненту, то их удаление возможно с помощью последовательного применения простых и сезонных разностных операторов. Порядок их применения не существенен:
3) Прогнозирование с помощью сезонной компоненты:
Для аддитивной модели:
![]()
Для мультипликативной модели:

2. Модели временного ряда: AR(p), MA(q), ARIMA(p,d,q). Идентификация моделей, оценка параметров, исследование адекватности модели, прогнозирование.
Для описания вероятностной компоненты временного ряда используют понятие случайного процесса.
Случайным процессом x(t), заданным на множестве Т, называют функцию от t, значения которой при каждом t T являются случайной величиной.
Случайные процессы, у которых вероятностные свойства не изменяются во времени, называются стационарными (матожидание и дисперсия – константы).
В качестве модели стационарных временных рядов чаще всего используются:
Скользящее среднее;
Их комбинации.
Для проверки стационарности ряда остатков и оценки его дисперсии используют:
Выборочную автокорреляционную функцию (коррелограмму);
Частную автокорреляционную функцию.
Пусть εt – процесс белого шума, т.е. в разные моменты времени t случайные величины εt независимы и одинаково распределены с параметрами M(εt)=0, D(εt)=σ2=const. Тогда:
Случайный процесс x(t) со средним значением μ называется процессом авторегрессии порядка p (AR(p)), если для него выполняется соотношение:
x(t)-μ= α1 (x(t-1) – μ) + α2 (x(t-2) – μ) +…+ αp (x(t-p) – μ) + εt
Случайный процесс x(t) называется процессом скользящего среднего порядка q (MA(q)), если для него выполняется соотношение:
x(t)= εt + β1 εt-1 +…+ βq εt-q
Случайный процесс x(t) называется процессом авторегрессии-скользящего среднего порядков p и q (ARMA(p,q)), если для него выполняется соотношение:
Нестационарные технические и экономические процессы могут быть описаны модифицированной моделью ARMA(p,q). Для удаления тренда можно использовать разностные операторы.
Пусть даны две последовательности U=(…,U-1,U0,U1,…) и V=(…,V-1, V0,V1,V2,…) такие, что:
Означает ,для
![]() означает и т.д.
означает и т.д.
Тогда процесс AR(p) представляется в виде ,
MA(q): ![]() ,
,
ARMA(p,q): ![]()
B можно использовать как разностный оператор, т.е. ![]()
эквивалентно V=(1-B)U
Для разностей второго порядка:
z =(1-B)V=(1-B)2U

где – разностный оператор порядка d; x=(1-B)dx.
Идентифицировать модель – определить ее параметры p, d и q. Для идентификации модели служат графики частных автокорреляционных (АКФ) и частных автокорреляционных функций (ЧАКФ).
АКФ. k-й член АКФ определяется по формуле:
 (*)
(*)
Параметр k называют лагом. На практике k < n/4. График АКФ – коррелограмма. Если полученный ряд остатков нестационарный, то по коррелограмма можно определить причины нестационарности.
Значения ЧАКФ akk находят, решая систему Юла – Уолкера, используя значения АКФ
Система Юла – Уолкера:
R1 = a1 + a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ ap
После визуализации ряда и удаления тренда рассматривается АКФ. Если график АКФ не имеет тенденции к затуханию, то это нестационарный процесс (модель ARIMA). При наличии сезонных колебаний коррелограмма содержит периодические всплески, как правило, соответствующие периоду колебаний. Рассматриваются разности 1-го, 2-го,…k-го порядка, пока ряд не станет стационарным, тогда параметр d=k (обычно k не больше 2). Переходят к идентификации стационарной модели.
Идентификация стационарных моделей:
АКФ плавно спадает;
ЧАКФ обрывается на лаге p.
АКФ обрывается на лаге q.
ЧАКФ плавно спадает.
Оценка параметров m, ai модели AR(p):
В качестве оценки m можно взять среднее значении ВР
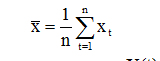
Для оценки ai найдем корреляцию между X(t) и X(t-k):
Общее решение этого уравнения относительно rk определяется корнями характеристического уравнения
Пусть корни характеристического уравнения различны. Тогда общее решение может быть записано в виде:
Из требования стационарности следует, что все |λi|<1.
Если записать уравнение (**) для k=1, 2, 3…., получим систему Юла-Уоркера для AR(p) процесса:
r1 = a1 +a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ap
Решая эту систему относительно a1, a2....ap, получим параметры AR(p).
Оценка параметра βi модели MA(q):
Для процесса МА(q) при |k| > q Cov = 0.
Cov = s2*(bk + b1*bk+1 + b2*bk+2 + … + bq-k*bq)
Отсюда автокорреляционная функция имеет вид:
 (***)
(***)
Для оценивания коэффициентов bi по наблюденному участку траектории существует несколько путей. Наиболее простой:
Находят
коэффициенты корреляции ![]() по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
Прогнозирование. При прогнозировании необходимо получить детерминированные значения ВР по уже имеющимся формулам, а затем рассчитать случайные значения по подобранной модели и скорректировать детерминированные значения на величину случайных значений.
3. Прогнозирование с помощью искусственных нейронных сетей, метод окон.
Решение математических задач с помощью нейронных сетей (НС) осуществляется путем обучение НС способам решения этих задач.
Обучение многослойной нейронной сети производится методом обратного распространения ошибки (Back Propagation).
Модель искусственного нейрона
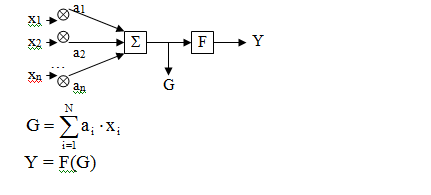
где xi – входные сигналы,
ai – коэффициенты проводимости (const), которые корректируются в процессе обучения,
F – функция активации, она нелинейная, в разных моделях может называться по-разному. Например, «сигмоида»:
Общая структура нейронной сети:

Скрытых слоев может быть несколько, поэтому НС – многослойная.
– вектор эталонных сигналов (желаемых)
yi – вектор реальных (выходных) сигналов
xi – вектор входных сигналов.
Стратегия обучения «обучение с учителем»
Типовые шаги:
1) Выбрать очередную обучающую пару из обучающего множества .
x – входной вектор;
– соответствующий ему желаемый (выходной вектор).
Подать входной вектор х на вход НС.
2) Вычислить выход сети у – реальный выходной сигнал.
Предварительно, весовые коэффициенты aij и bij задаются произвольно случайным образом.
3) Вычислить отклонение (ошибку): ![]()
4) Подкорректировать веса aij и bij сети так, чтобы минимизировать ошибку.
![]()
5) Повторить шаги 1– 4.
Процесс повторяется до тех пор, пока ошибка на всем обучающем множестве не уменьшится до требуемой величины.
Проход вперед сигнала X по сети:
Из обучающего множества берется пара. Для каждого слоя, начиная с первого, вычисляется Y: Y = F(X·A),
где A – матрица весов слоя;
F – функция активации.
Вычисления – слой за слоем.
Обратный проход ошибки по НС:
Выполняется подстройка весов выходного слоя. Для этого применяется модифицируемое дельта-правило.
Рис. Обучение одного веса от нейрона p в скрытом слое j к нейрону q в выходном слое k
Для выходного нейрона сначала находится сигнал ошибки
![]()
εq умножается на производную сжимающей функции , вычисленную для этого нейрона слоя k. Получаем величину δ:
Δapqk = α · δqk · ypj,
где α – коэффициент скорости обучения (0.01≤ α <1) – const, подбирается экспериментально в процесса обучения.
ypj – выходной сигнал нейрона p слоя j.
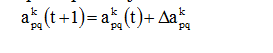 – величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
– величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
Подстройка весов скрытого слоя.
Рассмотрим нейрон скрытого слоя p. При переходе вперед этот нейрон передает свой выходной сигнал нейронам выходного слоя через соединяющие их веса. Во время обучения эти веса функционируют в обратном порядке, пропуская величину δ от выхода назад к скрытому слою.

И так для каждой пары. Процесс заканчивается, если для каждого X НС будет вырабатывать
Прогнозирование с помощью НС. Метод окон.
Задан временной ряд xt, t=1,2…T. Задача прогнозирования сводится к задаче распознавания образов на НС.
Метод выявления закономерности во временном ряде на основе НС называется “windowing” (метод окон).
Используется два окна Wi (input) и Wo (output) фиксированного размера n и m соответственно, для наблюдаемого множества данных.

Эти окна способны перемещаться с некоторым шагом S по кривой (ряду) вдоль оси времени. В результате получается некоторая последовательность наблюдений:

Первое окно Wi, сканирует данные, предает их на вход НС, а Wo – на выход. Получающаяся на каждом шаге пара Wji→Wj0, j=1..n образует обучающую пару (наблюдение). После обучения НС можно использовать для прогноза.
07.10.2013 Тайлер Чессман
Понимание ключевых идей прогнозирования временных рядов и ознакомление с некоторыми деталями даст вам преимущество в использовании возможностей прогнозирования в SQL Server Analysis Services (SSAS)
В этой статье будут описаны основные понятия, необходимые для освоения технологий интеллектуального анализа данных. Кроме того, мы рассмотрим некоторые тонкости, чтобы, столкнувшись с ними на практике, вы не были обескуражены (см. врезку «Почему интеллектуальный анализ данных так непопулярен»).
Время от времени специалистам по SQL Server приходится делать перспективные оценки будущей стоимости, например прогнозы доходов или продаж. Организации иногда применяют технологию интеллектуального анализа данных (data-mining) в построении моделей прогнозирования, чтобы предоставить такие оценки. Разобравшись в основных понятиях и некоторых деталях, вы начнете с успехом использовать возможности прогнозирования в SQL Server Analysis Services (SSAS).
Методы прогнозирования
Существуют различные подходы к прогнозированию. Например, сайт Forecasting Methods (forecastingmethods.org) выделяет различные категории методов прогнозирования, включая казуальные (иначе называемые экономико-математическими), экспертное моделирование (субъективные), временные ряды, искусственный интеллект, рынок прогнозов, вероятностное прогнозирование, моделирование прогнозирования, а также метод прогнозирования на основе референсных классов. Веб-сайт Forecasting Principles (www.forecastingprinciples.com) дает представление о методах в виде методологического дерева, прежде всего разделяя субъективные методы (то есть методы, используемые при недостатке имеющихся данных для количественного анализа) и статические (то есть методы, используемые, когда доступны соответствующие числовые данные). В этой статье я остановлюсь на прогнозировании временных рядов, типе статического подхода, в котором накопленных данных достаточно для прогнозирования показателей.
Прогнозирование временных рядов предполагает, что данные, полученные в прошлом, помогают объяснить значения в будущем. Важно понимать, что в ряде случаев мы имеем дело с деталями, не отраженными в накопленных данных. Например, появится новый конкурент, который может неблагоприятно повлиять на будущие доходы или быстрые изменения в составе рабочей силы, которые могут повлиять на показатели уровня безработицы. В подобных ситуациях прогнозирование временных рядов не может быть единственным подходом. Зачастую различные подходы к прогнозированию объединяют, чтобы обеспечить наиболее точные прогнозы.
Понимание основ прогнозирования временных рядов
Временные ряды – это совокупность значений, полученных в период времени, обычно через равные интервалы. Общие примеры включают количество продаж в неделю, квартальные расходы и уровни безработицы по месяцам. Данные временных рядов представлены в графическом формате, с временным интервалом вдоль оси координат x графика и значениями вдоль оси y, как показано на экране 1.
Если рассматривать, как меняется значение от одного периода до другого и как прогнозировать значения, следует иметь в виду, что данные временных рядов обладают некоторыми важными характеристиками.
- Базовый уровень (Base level). Базовый уровень, как правило, определяется как среднее значение временного ряда. В некоторых моделях прогнозирования базовый уровень обычно определяется как начальное значение данных ряда.
- Тренд (Trend). Тренд, как правило, показывает, как временные ряды изменяются от одного периода к другому. На примере, представленном на экране 1, число безработных имеет тенденцию роста с начала 2008 года до января 2010 года, после чего линия тренда направляется вниз. Информацию о совокупности выборочных данных, использованных для построения диаграмм в данной статье, можно найти во врезке «Расчет уровня безработицы».
- Сезонные колебания. Некоторые значения имеют тенденцию роста или снижения в зависимости от определенных периодов времени, это может быть день недели или месяц в году. Можно рассмотреть пример с продажами в розничных магазинах, пик которых часто приходится на рождественский сезон. В случае с безработицей мы видим сезонный тренд с наивысшими показателями в январе и июле и низкими показателями в мае и октябре, как показано на экране 2.
- Шум (Noise). Некоторые модели прогнозирования включают четвертую характеристику, шум, или ошибку, которая относится к случайным колебаниям и неравномерным движениям в данных. Шум мы здесь рассматривать не будем.
Таким образом, определяя тренд, накладывая линию тренда на базовый уровень и выявляя сезонную составляющую, которая может иметь место при анализе данных, вы получаете модель прогнозирования, которую можно задействовать для составления прогноза значений:
Прогнозируемое значение = Базовый уровень + Тренд + Сезонная составляющая
Определение базового уровня и тренда
Единственный способ определить базовое значение и тренд – это воспользоваться методом регрессии. Под словом «регрессия» здесь понимается рассмотрение взаимосвязи между переменными. В данном случае существует взаимосвязь между независимой переменной времени и зависимой переменной числа безработных. Обратите внимание, что независимая переменная иногда называется прогнозирующим параметром.
Воспользуйтесь таким инструментом, как Microsoft Excel, чтобы применить метод регрессии. Например, вы можете выполнить автоматический подсчет в Excel и добавить линию тренда к графику временных рядов, используя меню Trendline на вкладке Chart Tools Layout или вкладке PivotChart Tools Layout в панели Excel 2010 или Excel 2007. На экране 1 я добавил прямую линию тренда, выбрав режим Linear trendline в меню Trendline. Затем я выбрал More Trendline Options в меню Trendline, а потом – параметры Display Equation on chart («Показывать уравнение на диаграмме») и Display R-squared value on chart («Показывать на диаграмме значение коэффициента детерминации»), см. экран 3.
.jpg) |
| Экран 3. Параметры тренда в Excel |
Этот процесс подгонки линии тренда к накопленным данным называется линейной регрессией (linear regression). Как мы видим на экране 1, линия тренда рассчитывается в соответствии с уравнением, где определяется базовый уровень (8248,8) и тренд (104.67x):
y = 104,67x + 8248,8
Можно представить себе линию тренда как ряд связанных координат осей x-y, куда вы можете включить промежуток времени (то есть ось x) для получения значения (ось y). Excel определяет «лучшую» линию тренда, применяя метод наименьших квадратов (определяемый как R² на экране 1). Линия наименьших квадратов – это линия, которая минимизирует возведенное в квадрат расстояние по вертикали из каждой точки линии тренда к соответствующей точке линии. Среднеквадратические значения позволяют определить, что отклонения выше или ниже актуальной линии не уравновешивают друг друга. На экране 1 мы видим, что R² = 0,5039, то есть линейное соотношение объясняет 50,39 % изменений в статистике безработицы с течением времени.
Определение точной линии тренда в Excel часто включает в себя метод проб и ошибок, наряду с визуальным контролем. На экране 1 прямая линия тренда подходит не самым лучшим образом. Excel предлагает другие варианты линии тренда, которые вы видите на экране 3. На экране 4 я добавил линию скользящей средней за четыре периода, которая строится на основе среднего арифметического показателей текущего и последних установленных периодов временного ряда.
Кроме того, я добавил полиномиальную линию тренда, применив алгебраическое уравнение для построения линии. Заметьте, что полиномиальная линия тренда имеет значение R² - 0,9318, определяющее наилучшее соотношение в выражении связи между независимой и зависимой переменными. Однако более высокое значение R² не обязательно означает, что линия тренда обеспечит качество прогнозной оценки. Существуют другие методы расчета точных прогнозов, которые я вкратце опишу ниже. Некоторые варианты линии тренда в Excel (например, линейная, полиномиальная линии тренда) позволяют делать прогнозы вперед, а также в обратном направлении, с учетом количества периодов, с нанесением полученных значений на график. Кому-то может показаться странным выражение «прогноз в обратном направлении». Лучше всего представить это на примере. Предположим, что новый фактор - быстрое увеличение рабочих мест в государственном секторе (например, рабочие места в Homeland Defense в начале 2000-х годов, временные работники Бюро переписи населения США) - послужил причиной быстрого падения уровня безработицы. Вам нужно сделать прогноз темпов роста нового сектора рабочих мест в обратном направлении в течение нескольких месяцев, а затем пересчитать уровень безработицы, чтобы прийти к сглаженному показателю изменения.
Вы также можете вручную применить уравнение линии тренда для расчета значений на перспективу. На экране 5 я добавил полиномиальную линию тренда с прогнозом на 6 месяцев, сперва убрав данные за последние 6 месяцев (то есть с апреля по сентябрь 2012 года) из исходного временного ряда.
Если сравнить экран 5 с экраном 1, можно заметить, что полиномиальные прогнозы обладают тенденцией роста, что не соответствует нисходящей тенденции (тренду) фактического временного ряда.
Относительно регрессии важно сделать два замечания.
- Как уже упоминалось выше, линейная регрессия включает одну независимую и одну зависимую переменную. Для понимания того, как дополнительные независимые переменные могут объяснить изменения в зависимой переменной, попробуйте построить модель множественной регрессии. В контексте прогнозирования числа безработных в Соединенных Штатах вы можете увеличить R² (и точность прогноза), учитывая коэффициент роста экономики, населения США, а также рост числа нанятых работников. SSAS может вместить множество переменных (то есть регрессоров) в модель прогнозирования временных рядов.
- Алгоритмы прогнозирования временных рядов, включая те, что используются в SSAS, позволяют вычислить автокорреляцию, которая является корреляцией между соседними значениями временного ряда. Модель прогнозирования, которая непосредственно включает автокорреляцию, называется авторегрессивной (AR) моделью. Например, модель линейной регрессии выстраивает уравнение тренда на основе периода (например, 104,67 * x), в то время как в AR модели уравнение строится, исходя из предыдущих значений (например, -0,417 * безработных (-1) + 0,549 * занятых (-1)). AR модель потенциально увеличивает точность прогноза, так как учитывает дополнительную информацию сверх тренда и сезонной компоненты.
Учитываем сезонную составляющую
Сезонная компонента в структуре временного ряда обычно проявляется в связи либо с днем недели, либо с днем месяца, или же с месяцем в году. Как отмечалось выше, число безработных в США обычно растет и сокращается в установленный календарный год. Это верно даже при росте экономики, как показано на экране 2. Иными словами, чтобы сделать точный прогноз, вы должны учесть сезонную составляющую. Один общий подход заключается в применении метода сглаживания сезонных колебаний. В работе Practical Time Series Forecasting: A Hands-On Guide, Second Edition (CreateSpace Independent Publishing Platform, 2012) автор Галит Шмуели рекомендует использовать один из трех методов:
- вычисление скользящего среднего;
- анализ временного ряда на менее детализированном уровне (например, рассмотрите изменения числа безработных поквартально, а не по месяцам);
- анализ отдельных временных рядов (и расчет прогнозов) по сезону.
Базовый уровень и тренд определяются при расчете прогноза с учетом сглаженного временного ряда. Факультативно сезонная составляющая или корректировка могут вновь применяться к прогнозируемым значениям с учетом начальных значений сезонного фактора при работе с методом Хольта-Винтерса. Если вы хотите увидеть, как производятся расчеты с учетом фактора сезонности в Excel, введите в строке поиска в Интернете «метод Винтерса в Excel». Также развернутое объяснение метода Хольта-Винтерса можно найти в руководстве Wayne L. Winston Microsoft Office Excel 2007: Data Analysis and Business Modeling, Second Edition (Microsoft Press, 2007).
Во многих пакетах интеллектуального анализа данных, таких, как SSAS, в алгоритмах прогнозирования временных рядов автоматически учитываются сезонные колебания путем измерения сезонных соотношений и включения их в модель прогнозирования. Тем не менее, возможно, вы захотите установить подсказки о структуре сезонных изменений.
Точность измерений модели прогнозирования
Как уже говорилось, исходная модель (если применять метод наименьших квадратов) не обязательно обеспечивает точность прогнозов. Самый лучший способ проверки точности прогнозных оценок – это разделить временной ряд на два набора данных: один для построения (то есть тренировки) модели и другой – для валидации. Набор данных для валидации будет являться наиболее «свежей» частью в наборе исходных данных, и он идеально охватывает время, равное временной шкале прогноза на будущее. Для проверки (валидации) модели предсказанные значения сравниваются с фактическими значениями. Обратите внимание, что после того, как вы произвели валидацию, модель может быть перестроена с использованием всего временного ряда, так что для прогнозирования будущих значений показателей желательно задействовать новейшие фактические значения.
Когда измеряется точность модели прогнозирования, как правило, возникает два вопроса: как определить точность прогнозной оценки и сколько исторических данных использовать для тренировки модели.
Как определить точность прогнозной оценки? В некоторых сценариях значения, прогнозируемые выше фактических значений, могут быть нежелательны (например, в прогнозах относительно инвестиционной деятельности). В других ситуациях значения, прогнозируемые ниже фактических, могут иметь разрушительные последствия (например, прогнозирование минимальной из выигрышных цен пункта аукциона). Но в случаях, когда вы хотите рассчитать оценку для всех прогнозов (неважно, выше или ниже реальных значений оказываются прогнозные значения), вы можете начать с количественной ошибки в отдельном прогнозе, используя определение:
ошибка = прогнозируемое значение – фактическое значение
При таком определении ошибки есть два популярнейших метода для измерения точности: это средняя абсолютная ошибка, то есть mean absolute error (MAE) и средняя абсолютная ошибка в процентах, или mean absolute percentage error (MAPE). В методе MAE абсолютные значения ошибок прогнозирования суммируются, а затем делятся на общее число прогнозов. Методом MAPE рассчитывается среднее абсолютное отклонение от прогноза в процентах. Для просмотра примеров работы с этими и другими методами для измерения качества прогнозных оценок шаблон Excel (с образцом данных прогнозирования и коэффициентами точности) откройте веб-страницу Demand Metrics Diagnostics Template (demandplanning.net/DemandMetricsExcelTemp.htm).
Сколько исторических данных следует использовать для тренировки модели? Работая с временным рядом, история которого уходит далеко в прошлое, вы можете захотеть включить в модель все исторические данные. Однако подчас дополнительная история не повышает точность прогнозирования. Давние данные могут даже исказить прогноз, если условия в прошлом существенно отличаются от условий в настоящем (например, состав рабочей силы сейчас и в прошлом различен). Мне не попадалась какая-то особая формула или практический метод, которые подсказали бы, какое количество исторических данных необходимо включить, поэтому я предлагаю начать с временных рядов, которые в несколько раз больше, чем временные интервалы прогноза, а затем проверить точность. Далее, попробуйте округлить число истории вверх или вниз и проведите тест повторно.
Прогнозирование временных рядов в SSAS
Прогнозирование временных рядов впервые появилось в SSAS в 2005 году. Для вычисления прогнозных значений алгоритм временных рядов Microsoft (Microsoft Time Series) использовался единый алгоритм под названием autoregressive tree with cross prediction (ARTXP), или дерево с авторегрессией с перекрестным прогнозированием. ARTXP сочетает метод авторегрессии с интеллектуальным анализом данных decision tree (дерево решений), так что уравнение прогноза может измениться (имеется в виду разделение) на основе определенных критериев. Например, модель прогнозирования обеспечит лучшее соответствие (и большую точность прогноза), если сначала предпринять разделение по дате, а затем на основе значения независимой переменной, как показано на экране 6.
.jpg) |
| Экран 6. Пример дерева решения ARTXP в SSAS |
В SSAS 2008 в алгоритме Microsoft Time Series в дополнение к ARTXP начал использоваться алгоритм под названием autoregressive integrated moving average (ARIMA), интегрированное скользящее среднее с авторегрессией, для вычисления долгосрочных прогнозов. ARIMA считается отраслевым стандартом и может рассматриваться как сочетание процессов авторегрессии и моделей скользящего среднего. Кроме того, он анализирует исторические ошибки прогнозирования для улучшения модели.
По умолчанию алгоритм Microsoft Time Series сочетает результаты алгоритмов ARIMA и ARTXP для достижения оптимальных прогнозов. По желанию вы можете отменить данную функцию. Обратимся к документации SQL Server Books Online (BOL):
«Алгоритм тренирует две различные модели одних и тех же данных: одна модель использует алгоритм ARTXP, а другая – алгоритм ARIMA. Затем алгоритм объединяет результаты двух моделей, чтобы разработать наилучший прогноз, охватывающий переменное число временных срезов. Поскольку алгоритм ARTXP больше подходит для краткосрочных прогнозов, им желательно воспользоваться в начале ряда прогнозов. Однако если временные срезы, необходимые для прогнозирования, уходят в будущее, алгоритм ARIMA более значим».
При работе с прогнозированием временных рядов в SSAS вы должны постоянно иметь в виду следующее:
- Хотя в SSAS есть закладка Mining Accuracy Chart, она не работает с интеллектуальным анализом данных для моделей временных рядов. В результате вам следует вручную измерять точность с помощью одного из методов, упомянутых здесь (например, MAE, MAPE), используя для расчетов такой инструмент, как Excel.
- Редакция SSAS Enterprise Edition позволяет разделить один временной ряд на множество «исторических моделей», так что вам не нужно будет вручную разделять данные на наборы данных для тренировки модели и валидации, проверяя точность прогноза. С точки зрения конечного пользователя, есть только одна модель временных рядов, но вы можете сравнить фактические результаты с прогнозируемыми в рамках модели, как показано на экране 7. Если вы не работаете с редакцией Enterprise Edition или не хотите использовать эту функцию, прежде всего вручную разделите данные.
Следующий шаг
В этой статье я познакомил вас с основами прогнозирования временных рядов. Мы также рассмотрели некоторые детали базовых алгоритмов, чтобы они не стали препятствием в обработке временных рядов. В качестве следующего шага я предлагаю вам освоить инструменты прогнозирования временных рядов с SSAS. Образцом может послужить проект, в котором используются данные по безработице, приведенные в данной статье. Затем вы можете ознакомиться с электронным учебным пособием TechNet «Intermediate Data Mining Tutorial (Analysis Services – Data Mining)» (Промежуточные итоги интеллектуального анализа данных (Analysis Services – интеллектуальный анализ данных)) по адресу technet.microsoft.com/en-us/library/cc879271.aspx.
Почему интеллектуальный анализ данных так непопулярен
В последнее десятилетие начали широко применяться технологии бизнес-аналитики business intelligence (BI), такие, как OLAP. В то же время Microsoft занялась продвижением другой BI–технологии, интеллектуального анализа данных, в таких популярных инструментах, как Microsoft SQL Server и Microsoft Excel. Однако технология интеллектуального анализа данных пока не стала ведущей. Почему? Хотя большинство людей может быстро ухватить суть ключевых понятий интеллектуального анализа данных, основные детали алгоритмов неразрывно связаны с математическими понятиями и формулами. Существует большое «расхождение» между высоким уровнем абстрактного понимания и детальным исполнением. В результате интеллектуальный анализ данных рассматривается ИТ-специалистами и промышленными клиентами как «черный ящик», что не способствует широкому внедрению технологии. Данная статья – моя попытка уменьшить «расхождение» в прогнозировании временных рядов.
Расчет уровня безработицы
В основной статье данные для графиков взяты с учетом информации о работающем населении, опубликованной U.S. Bureau of Labor Statistics (http://www.bls.gov/). BLS публикует сведения об уровне безработицы на основании ежемесячного опроса, проводимого Бюро переписи населения США (BLS), экстраполирующего общее число работающих и безработных. В частности, BLS применяет формулу:
Уровень безработицы = безработные/(безработные + работающие)
Примечательно, что, когда речь заходит об уровне безработицы, средства массовой информации обычно приводят выровненный коэффициент сезонности. Сезонная корректировка осуществляется с помощью общей модели, которая называется авторегрессионным проинтегрированным скользящим средним – autoregressive integrated moving average (ARIMA). По сути, это тот же алгоритм, что используется во многих пакетах глубинного анализа данных для прогнозирования временных рядов, включая SQL Server Analysis Services (SSAS). Чтобы получить более подробную информацию о модели ARIMA, используемой BLS, зайдите на веб-страницу X-12-ARIMA Seasonal Adjustment Program (www.census.gov/srd/www/x12a/). Обратите внимание, что в типовом проекте для данной статьи я использовал скорректированные значения сезонных и несезонных колебаний.
Осваиваем прогнозирование временных рядов